7. Parallel calculation
Basis |
Device |
Level |
Usage |
Notes |
|---|---|---|---|---|
Real |
CPU |
MPI\(_\text{bnd}\) |
\(n_{MPI} \leq n_{bnd}\) |
|
Real |
CPU |
MPI\(_\text{kpt}\) |
\(n_{MPI} \leq n_{kpt}\) |
|
Real |
GPU |
MPI\(_\text{bnd}\) |
\(n_{GPU} \leq n_{bnd}\) |
|
Real |
GPU |
MPI\(_\text{kpt}\) |
\(n_{GPU} \leq n_{kpt}\) |
|
LCAO |
CPU |
MPI\(_\text{nao}\) |
\(n_{MPI} \leq n_{nao}\) |
|
LCAO |
CPU |
MPI\(_\text{kpt}\) |
\(n_{MPI} \leq n_{kpt}\) |
|
LCAO |
GPU |
MPI\(_\text{nao}\) |
unavailable |
|
LCAO |
GPU |
MPI\(_\text{kpt}\) |
\(n_{GPU} \leq n_{kpt}\) |
\(n_{MPI} = n_{GPU}\) |
In principle, RESCU can exploit any number of processes and cores. In practice, using the proper resources requires some thought, but may save you a lot of time. You may find RESCU’s basic guiding principles in Table 7.1 and additional details in the following sections.
7.1. CPU
Library |
Variable |
|---|---|
BLAS |
OMP_NUM_THREADS |
MKL |
MKL_NUM_THREADS |
OpenBLAS |
OPENBLAS_NUM_THREADS |
GotoBLAS |
GOTO_NUM_THREADS |
In this section, we discuss the parallelization parameters when executing RESCU on regular CPUs. The case where GPU devices are added to the mix is discussed in section GPU.
In real space calculations (LCAO.status = false), RESCU parallelizes
either bands (and grid points) or k-points. The default scheme is band
parallelization since it is most scalable, and RESCU is oriented toward
large system research. In linear combination of atomic orbital (LCAO)
calculations (LCAO.status = true), RESCU parallelizes either
orbitals or k-points, and the default scheme is orbital parallelization.
Additional parallelization comes from threading linear algebra
operations. This is usually done automatically by MATLAB unless
otherwise specified (e.g. using the -singleCompThread option). When
several instances of MATLAB are running on the same node, it is
preferable to bind processes to cores and specify explicitly the amount
of threading to employ. This is done as follows
export ONT=4 && export PPN=$((32/ONT))
export OPENBLAS_NUM_THREADS=$ONT
MATCMD="matlab -nodisplay -nojvm -nosplash -r"
mpiexec --map-by ppr:$PPN:node:pe=$ONT $MATCMD "rescu -i $INPUTFILE.input"
In this example, each node has 32 cores shared by 8 MPI processes
(PPN), and hence we use 4-way threading (ONT). We explicitly
tell OpenBLAS to use 4 threads by setting OPENBLAS_NUM_THREADS; not
doing so may result in terrible performance on some systems. Then we
define the MATCMD variable which holds the matlab command and
options. Finally, we call mpiexec with the --map-by option. The
keyword ppr indicates how many processes to spawn per computing
resource. We set the number of processes to PPN and the resource to
node in this example, but other resource objects such as socket
are allowed. Each process is bound to ONT processing elements
(cores) as indicated by the segment pe=$ONT. A complete SLURM
submission script could look as follows
\##!/bin/bash
#SBATCH --nodes=2 --ntasks-per-node=8
#SBATCH --cpus-per-task=4 --mem=0
#SBATCH --time=12:00:00 --job-name=rescu-test
#SBATCH --output=./mpi_ex_%j.out
#SBATCH --error=./mpi_ex_%j.err
INPUTFILE=scf
export ONT=$SLURM_CPUS_PER_TASK
export PPN=$((32/ONT))
export OPENBLAS_NUM_THREADS=$ONT
MATCMD="matlab -nodisplay -nojvm -nosplash -r"
cd $SLURM_SUBMIT_DIR
mpiexec --map-by ppr:$PPN:node:pe=$ONT $MATCMD "rescu -i $INPUTFILE.input"
As mentioned in Table 7.1, the number of MPI processes should be inferior to the number of bands. This is not to say that you cannot use less cores than bands since an MPI process can use a whole socket or even a whole node efficiently.
Small systems have a small number of bands, but typically require
sampling the Brillouin with several k-points. It is then favorable to
parallelize over k-points (mpi.parak = true) since the main
bottleneck, diagonalizing the Kohn-Sham Hamiltonian, is independent with
respect to the k-point index. The number of MPI processes should be
inferior to the number of k-points; the number of MPI processes in
excess will simply be idle. If the number of cores exceeds the number of
k-points, simply resort to threading as explained previously.
7.2. GPU
In this section, we introduce an example of a parallel GPU calculation. GPUs accelerate certain demanding linear algebra operations. The input file to calculate the ground-state density of a hBN-InSe heterostructure is found below.
smi.status = 1
gpu.status = 1
gpu.procpernode = 16
info.calculationType = 'self-consistent'
info.savepath = './InSe_BN_3-5ab'
diffop.method = 'fd'
element(1).species = 'In'
element(1).path = '../pdata_siegga/In_TM_PBE.mat'
element(2).species = 'Se'
element(2).path = '../pdata_siegga/Se_TM_PBE.mat'
element(3).species = 'B'
element(3).path = '../pdata_siegga/B_TM_PBE.mat'
element(4).species = 'N'
element(4).path = '../pdata_siegga/N_TM_PBE.mat'
atom.fracxyz = '3-5IBab-2d.xyz'
domain.latvec = [12.3966999054 0 0; -6.1983499527 10.7358570412 0; 0 0 24.1581993103]/0.529117
domain.lowres = 0.4
eigensolver.algo = 'cfsi'
functional.libxc = 1
functional.list = {'XC_GGA_X_OPTPBE_VDW','XC_GGA_C_OP_PBE'}
The input file for a GPU-accelerated calculation is similar to regular
input files. The xyz-file 3-5IBab-2d.xyz is not reproduced here as
it includes thousands of lines. The relevant keywords are highlighted
and discussed next.
gpu.statusdetermines whether to use GPU devices. This keyword can be omitted if the –gpu option is passed in the command line;gpu.procpernodedetermines how many how many MPI processes per node will be initialized. This keyword is optional as RESCU can generally detect the correct value by itself. RESCU requiresgpu.procpernodeto affiliate GPUs and MPI processes, and hence the value should be an integer divisible by the number of GPUs per node;diffop.methodwhile this keyword is not mandatory, it is advised to use the’fd’method in large systems for optimal performance.
Using a heterogeneous computing system optimally requires more thought than regular CPU-based computers do. We shall introduce a few considerations which may impact performance.
First, let’s recall how to control CPU affinity. RESCU often performs
best on pure CPU architectures when each process is controlled by one
core, i.e. threading is turned off. One can initialized as many
processes as there are cores using the mpirun command option
--map-by node:PE=1. Additionally, the matlab startup option
-singleCompThread forces a MATLAB instance to use a single core. We
should also prevent an external BLAS library to thread linear algebra
operations. If mpirun initiated one process per core, not doing so
will likely decrease performance. BLAS library threading is usually
control by the environment variables found in
Table 7.1.1. For example, if RESCU links MKL,
then MKL_NUM_THREADS should be set to 1. To summarize, we can force
each process to use a single core as follows
export OPENBLAS_NUM_THREADS=1
export MATCMD="matlab -nojvm -nosplash -nodisplay -singleCompThread -r"
mpirun --map-by node:PE=1 $MATCMD "runrescu"
and we can force each process to use a three cores as follows
export OPENBLAS_NUM_THREADS=3
export MATCMD="matlab -nojvm -nosplash -nodisplay -r"
mpirun --map-by node:PE=3 $MATCMD "runrescu"
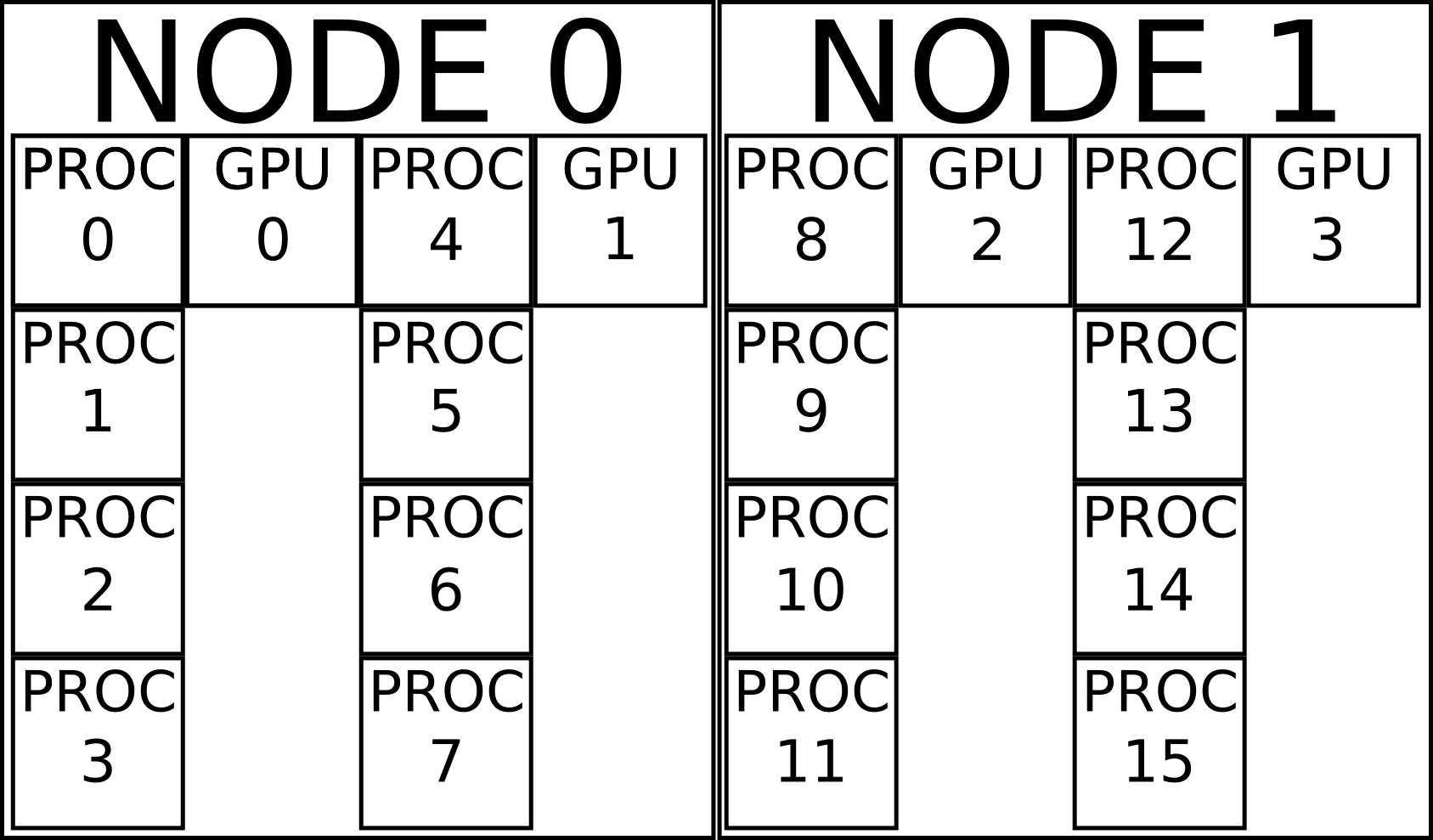
Fig. 7.2.1 Illustration of GPU affinity. MPI processes are attributed sequentially across nodes. MPI processes are split in equal groups (each column is a group). A GPU is associated to each group. Each GPU is controlled by the root process of its group (first row of each column).
With that in mind, let’s turn to GPU affinity. RESCU requires that the number of MPI processes per node be divisible by the number of GPU per node. RESCU split the process pool in equal groups and associate a group with each GPU as illustrated in Fig. 7.2.1. The GPU is controlled by the root process of each group (first row processes in Fig. 7.2.1). It follows that other processes must pass by the root to communicate with the GPU, which may incur a significant communication cost if the groups are too large. The bottleneck is alleviated by using the proper amount of threading. For example, suppose a user would like to use two nodes, each having 16 cores and 2 GPUs (see Fig. 7.2.1). He determines that a group size of 4 is optimal, which means that 4 processes are associated with each GPU. 8 processes are thus spawned on each node and 2 cores bound to each process. Then RESCU may be run as follows
export OPENBLAS_NUM_THREADS=2
export MATCMD="matlab -nojvm -nosplash -nodisplay -r"
mpirun --map-by ppr:8:node:PE=2 $MATCMD "runrescu"